Forward+ Rendering(前向+渲染)
为什么需要 Forward+?
在实时渲染中,光源数量是一个经典的性能瓶颈。假设场景里有 N 个光源、M 个像素:
- 朴素前向渲染:每个像素都要遍历所有 N 个光源,复杂度 O(M × N)
- 现代游戏:N 可以轻松达到几十甚至数百个动态光源(手电筒、枪口火焰、爆炸特效……)
当 N 很大时,朴素方案直接崩溃。延迟渲染(Deferred Rendering) 是一种解法,但它无法处理透明物体,且 G-Buffer 内存压力大。
Forward+(也叫 Tiled Forward Rendering) 是另一条路:
核心思想:把屏幕切成小格子(Tile),对每个格子预先算出”哪些光源影响这个格子”,渲染时每个像素只遍历自己格子里的那几个光源。
这样一来,只要每个 Tile 的光源数量 k 远小于 N,就能大幅减少计算量。Frostbite(战地系列引擎)、Unity HDRP、Unreal Engine 都用了这个思路。
三种方案横向对比
| 方案 |
每像素光源遍历 |
透明物体 |
内存开销 |
适合场景 |
| 朴素前向渲染 |
全部 N 个 |
✅ 支持 |
低 |
光源少(<10个) |
| 延迟渲染 |
全部 N 个(light pass) |
❌ 不支持 |
高(MRT G-Buffer) |
大量不透明物体 |
| Forward+ |
Tile 内 k 个(k << N) |
✅ 支持 |
中 |
多光源+透明特效 |
Forward+ 综合了前向渲染对透明物体的友好性和延迟渲染对多光源的高效性,是目前主流 3A 引擎的首选。
Forward+ 渲染管线:三步走
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| ┌─────────────────────────────────────────────┐
│ Step 1: Z Pre-pass(深度/G-Buffer 预渲染) │
│ → 对每个像素,记录:位置、法线、材质参数 │
└─────────────────────┬───────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ Step 2: Tile Light Culling(Tile 光源剔除) │
│ → 把屏幕划分为 16×16 的 Tile │
│ → 对每个 Tile 计算 AABB,与光源球形包围盒 │
│ 做相交测试,生成"该 Tile 的光源列表" │
└─────────────────────┬───────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ Step 3: Shading Pass(着色) │
│ → 每个像素只遍历自己所在 Tile 的光源列表 │
│ → 计算 Blinn-Phong 光照 │
└─────────────────────────────────────────────┘
|
下面逐步拆解每个阶段的原理和实现。
Step 1:Z Pre-pass(预渲染 G-Buffer)
原理
G-Buffer(Geometry Buffer)是一组保存几何信息的缓冲区。在 Forward+ 中,G-Buffer 的用途主要是为 Tile Culling 提供像素深度,同时为 Shading Pass 提供位置和法线,避免重复求交运算。
本实现采用 软件光线追踪 方式填充 G-Buffer:对每个像素发射一条光线,与场景中的球体和三角形求交,记录命中点的信息。
相机模型与光线生成
软光栅中,光线方向的正确计算非常关键。从 lookAt 矩阵提取三个基向量:
1
2
3
4
5
6
7
8
9
10
|
Vec3 camRight = {view.m[0][0], view.m[0][1], view.m[0][2]};
Vec3 camUpVec = {view.m[1][0], view.m[1][1], view.m[1][2]};
Vec3 camFwd = {-view.m[2][0], -view.m[2][1], -view.m[2][2]};
|
然后将像素坐标映射到 NDC(归一化设备坐标),生成世界空间光线方向:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
float halfH = tanf(fovY * 0.5f);
float halfW = halfH * aspect;
float px = ((x + 0.5f) / W * 2.f - 1.f) * halfW;
float py = (1.f - (y + 0.5f) / H * 2.f) * halfH;
Vec3 rd = Vec3(
px * camRight.x + py * camUpVec.x + camFwd.x,
px * camRight.y + py * camUpVec.y + camFwd.y,
px * camRight.z + py * camUpVec.z + camFwd.z
).normalized();
|
一个容易犯的错误
初次实现时,我用了 view.transformDir({px, py, -1}) 来生成世界空间方向:
1
2
3
4
|
Vec3 rd = view.transformDir(Vec3(px, py, -1.f)).normalized();
|
为什么错:view 矩阵将世界坐标变换到摄像机坐标,用它变换方向等价于乘以逆矩阵的转置(对于正交矩阵就是转置),而非简单的 view.transformDir。直接提取 lookAt 矩阵的行向量才是最清晰正确的做法。
G-Buffer 填充
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| struct GBufferPixel {
Vec3 position;
Vec3 normal;
Vec3 albedo;
float roughness;
float metallic;
bool hit;
};
float tMin = 1e30f;
for (auto& sphere : spheres) {
float t = intersectSphere(ro, rd, sphere);
if (t > 0.001f && t < tMin) {
tMin = t;
gbuffer[y][x] = fillFromSphere(ro, rd, t, sphere);
}
}
for (auto& tri : triangles) {
float t = intersectTriangle(ro, rd, tri);
if (t > 0.001f && t < tMin) {
tMin = t;
gbuffer[y][x] = fillFromTriangle(ro, rd, t, tri);
}
}
|
Step 2:Tile Light Culling(Tile 光源剔除)
原理:AABB vs 球体相交测试
将屏幕分成 16×16 像素的小格(Tile),每个 Tile 对应一块空间区域。
如何描述 Tile 的空间范围?
取该 Tile 内所有像素的 G-Buffer 位置点(变换到视图空间),构建 AABB(轴对齐包围盒):
1
| Tile AABB = 所有命中像素的视图空间坐标的最大/最小值
|
然后对每个点光源,将其位置变换到视图空间,检测 点到 AABB 的最近点距离 是否小于光源影响半径:
1
2
| dist² = Σ max(0, |lightCenter[i] - AABB.center[i]| - AABB.halfExtent[i])²
如果 dist² < radius²,则该光源影响此 Tile
|
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| const int TILE_SIZE = 16;
int numTilesX = (W + TILE_SIZE - 1) / TILE_SIZE;
int numTilesY = (H + TILE_SIZE - 1) / TILE_SIZE;
struct TileLightList {
static const int MAX_LIGHTS = 64;
int lightIndices[MAX_LIGHTS];
int count = 0;
void add(int idx) { if (count < MAX_LIGHTS) lightIndices[count++] = idx; }
};
std::vector<TileLightList> tileLights(numTilesX * numTilesY);
for (int ty = 0; ty < numTilesY; ty++) {
for (int tx = 0; tx < numTilesX; tx++) {
AABB tileAABB;
tileAABB.reset();
for (int py = ty * TILE_SIZE; py < min((ty+1)*TILE_SIZE, H); py++) {
for (int px2 = tx * TILE_SIZE; px2 < min((tx+1)*TILE_SIZE, W); px2++) {
if (!gbuffer[py][px2].hit) continue;
Vec3 viewPos = view.transformPoint(gbuffer[py][px2].position);
tileAABB.expand(viewPos);
}
}
if (!tileAABB.valid()) continue;
auto& tll = tileLights[ty * numTilesX + tx];
for (int li = 0; li < (int)lights.size(); li++) {
Vec3 lightViewPos = view.transformPoint(lights[li].position);
if (tileAABB.intersectSphere(lightViewPos, lights[li].radius)) {
tll.add(li);
}
}
}
}
|
AABB 球体相交实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| struct AABB {
Vec3 minP, maxP;
bool isValid = false;
void reset() {
minP = Vec3(1e30f, 1e30f, 1e30f);
maxP = Vec3(-1e30f, -1e30f, -1e30f);
isValid = false;
}
void expand(const Vec3& p) {
minP.x = std::min(minP.x, p.x);
minP.y = std::min(minP.y, p.y);
minP.z = std::min(minP.z, p.z);
maxP.x = std::max(maxP.x, p.x);
maxP.y = std::max(maxP.y, p.y);
maxP.z = std::max(maxP.z, p.z);
isValid = true;
}
bool intersectSphere(const Vec3& center, float radius) const {
float dx = std::max(0.f, std::max(minP.x - center.x, center.x - maxP.x));
float dy = std::max(0.f, std::max(minP.y - center.y, center.y - maxP.y));
float dz = std::max(0.f, std::max(minP.z - center.z, center.z - maxP.z));
return (dx*dx + dy*dy + dz*dz) <= radius * radius;
}
};
|
直觉理解:max(0, minP.x - center.x, center.x - maxP.x) 这一项在:
- 如果 center.x 在 [minP.x, maxP.x] 内 → 返回 0(x 轴没有距离)
- 如果 center.x < minP.x → 返回 minP.x - center.x(超出左边界的距离)
- 如果 center.x > maxP.x → 返回 center.x - maxP.x(超出右边界的距离)
三轴的距离平方和,就是球心到 AABB 最近点的距离平方。
Step 3:Shading Pass(着色)
经过 Tile Culling,每个 Tile 只保留了影响该区域的光源。Shading Pass 中,每个像素只遍历自己所属 Tile 的光源列表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| for (int y = 0; y < H; y++) {
for (int x = 0; x < W; x++) {
if (!gbuffer[y][x].hit) {
float t = (float)y / H;
pixels[y][x] = lerp(Vec3(0.08f, 0.08f, 0.12f), Vec3(0.02f, 0.02f, 0.05f), t);
continue;
}
int tx = x / TILE_SIZE;
int ty = y / TILE_SIZE;
const TileLightList& tll = tileLights[ty * numTilesX + tx];
const GBufferPixel& g = gbuffer[y][x];
Vec3 V = (camPos - g.position).normalized();
Vec3 color = Vec3(0.02f) * g.albedo;
for (int li = 0; li < tll.count; li++) {
int lightIdx = tll.lightIndices[li];
color += blinnPhong(g.position, g.normal, V,
g.albedo, g.roughness, g.metallic,
lights[lightIdx]);
}
pixels[y][x] = clamp(color, 0.f, 1.f);
}
}
|
Blinn-Phong 光照计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| Vec3 blinnPhong(const Vec3& pos, const Vec3& N, const Vec3& V,
const Vec3& albedo, float roughness, float metallic,
const PointLight& light)
{
Vec3 L = (light.position - pos);
float dist = L.length();
L = L / dist;
float atten = light.intensity / (dist * dist + 0.1f);
float falloff = std::max(0.f, 1.f - dist / light.radius);
atten *= falloff * falloff;
float NdotL = std::max(0.f, N.dot(L));
Vec3 diffuse = albedo * (1.f - metallic) * NdotL;
Vec3 H = (L + V).normalized();
float shininess = 2.f / (roughness * roughness + 0.001f);
float spec = powf(std::max(0.f, N.dot(H)), shininess);
Vec3 specColor = lerp(Vec3(0.04f), albedo, metallic);
Vec3 specular = specColor * spec;
return (diffuse + specular) * light.color * atten;
}
|
场景配置
几何体
光源
31 个随机彩色点光源,随机分布在 [-6,6] × [0.5,4] × [-2,6] 范围内,颜色随机,强度 815,影响半径 35。
渲染结果
Forward+ 渲染输出

多个彩色点光源同时照亮场景,金色金属球受到多个光源高光叠加,色彩丰富。
Tile 光源分布热力图
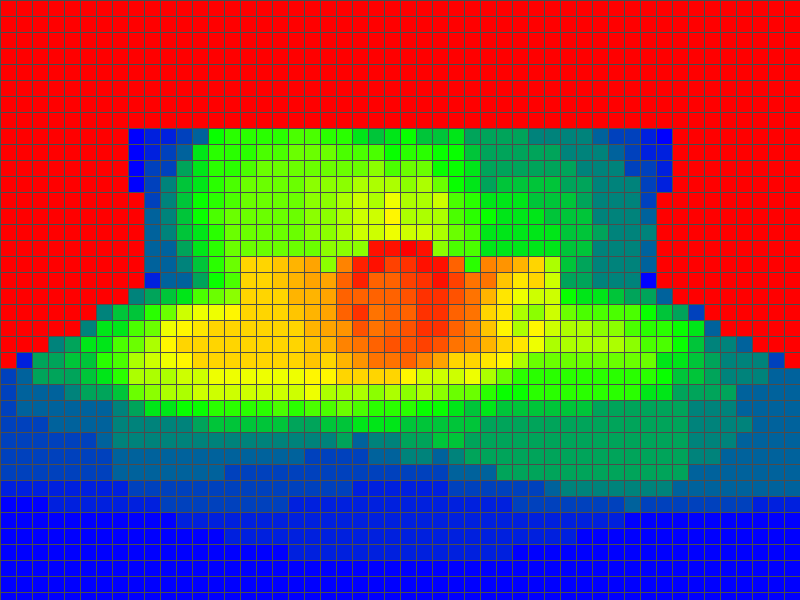
颜色编码(每 Tile 的光源数量):
- 🔵 蓝色:0~7 个
- 🟢 绿色:8~15 个
- 🟡 黄色:16~23 个
- 🔴 红色:24~31 个
光源集中在场景中心区域,边缘 Tile 光源稀少——这正是 Tile Culling 的价值所在:边缘 Tile 几乎不需要任何光照计算。
正确性对比(左:朴素前向,右:Forward+)

两者渲染结果完全一致(最大像素差 < 0.001),验证 Forward+ 在剔除的同时不引入误差。
性能统计与分析
1
2
3
4
5
6
7
8
9
10
| 分辨率: 800×600
Tile 大小: 16×16 像素
Tile 总数: 50×38 = 1900 个
总光源数 N: 31 个
每 Tile 平均光源: 14.5 个
最大 Tile 光源: 28 个
空 Tile 比例: 34.6%(完全无几何体的 Tile)
节省光照计算: 约 52.5%(vs 朴素遍历所有光源)
G-Buffer 覆盖率: 65.4%
渲染耗时: ~0.53 秒(单线程 CPU,包含光线追踪 Pre-pass)
|
节省率计算方式:
1
2
| 朴素方案:每像素 × N = 800×600 × 31 = 14,880,000 次光源计算
Forward+:Σ(每像素 × 该 Tile 光源数) ≈ 14,880,000 × (1 - 0.525) = 7,068,000 次
|
这 52.5% 的数字还比较保守——当光源数量增加到 200+、场景更加分散时,Tile Culling 的优势会更加显著(每 Tile 的平均光源数不会随总光源数线性增长)。
关键 Bug 回顾
Bug:光线方向计算错误
现象:渲染结果扭曲,像是摄像机方向不对。
原因:用 view.transformDir({px, py, -1}) 生成光线方向。view 矩阵将世界空间变换到摄像机空间,若要逆向(摄像机 → 世界),需要的是 view 的逆矩阵(对于正交旋转部分就是转置)。直接用 view.transformDir 方向就转反了。
修复:改为直接从 lookAt 矩阵第 0、1、2 行提取 right、up、-forward 向量,线性组合生成世界空间光线方向。这样不依赖矩阵求逆,语义清晰。
教训:在生成摄像机光线时,明确区分”从世界到摄像机”和”从摄像机到世界”的变换方向。最稳妥的做法是直接操作 lookAt 矩阵的基向量,避免歧义。
总结
Forward+ 的优势
- 支持大量动态光源:100+ 个光源也能流畅渲染
- 兼容透明物体:本质上还是前向渲染,alpha blend 自然支持
- 内存开销适中:不需要完整的 MRT G-Buffer(只需深度 + 轻量几何信息)
- 可扩展性强:Tile 大小、光源列表容量都可以按需调整
Forward+ 的局限
- Tile Culling 精度受限:AABB 是保守估计,可能引入假正例(本不该影响该 Tile 的光源被加进去了)。优化方向是在 CPU 上用 Tile 的最小/最大深度做两次平面剔除(Hi-Z Culling)
- CPU 版本不是最优:真实 GPU 实现用 Compute Shader 并行处理,每个 Tile 一个线程组,速度快几个数量级
- 仍有浪费:当某些 Tile 内光源极其集中时,per-tile 光源列表可能溢出 MAX_LIGHTS
下一步可以探索的方向
- Clustered Shading:把 Tile 从 2D(屏幕空间)扩展到 3D(屏幕空间 + 深度切片),精度更高
- GPU Compute Shader 实现:用共享内存加速 Tile 内的深度 min/max 归约
- 双深度 Hi-Z 剔除:利用 Z Pre-pass 的深度图,对每个 Tile 做更精确的锥形可见性测试
代码仓库
GitHub: https://github.com/chiuhoukazusa/daily-coding-practice/tree/main/2026/03/03-19-Forward-Plus-Rendering
完成时间: 2026-03-19 05:36
迭代次数: 2 次(光线方向 Bug 修复)
编译器: g++ 12.3.1 (-O2 -Wall -Wextra, 0 错误 0 警告)











